Initialization of weights at first glance looks a small and less useful step in deciding other factors of a CNN but actually it has can put a huge impact over convergence rate and quality of CNN network.
There is a common practice of choosing magnitude of initial weights to be as minimum as possible or near to zero but not zero at all.
There are many ways of weight initialization:
1. Initialization with zeros
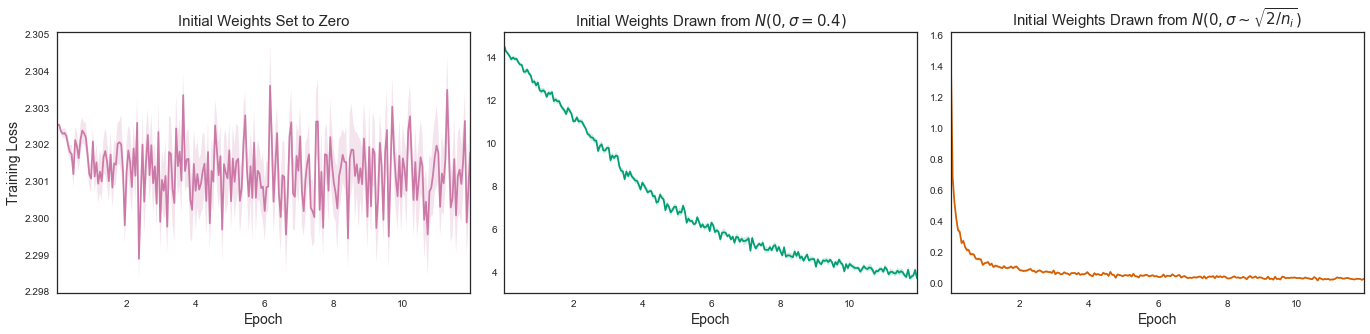
Initialization with zeros will result in no learning at all. The left most figure in the following diagram shows a graph between the Training Loss VS Epochs for training a simple CNN over MNIST dataset. The batch size was 128 images and no. of Epoch were 12.
2. Initialization with ones
3. Initialization with constants
4. Initialization with Normal Random Values (
Initialization with values with normal distribution
5. Initialization with Uniform Random Values
6. Initialization with Truncated Normal Random Values(
7. Initialization with Variance Scaled Values (
There is a common practice of choosing magnitude of initial weights to be as minimum as possible or near to zero but not zero at all.
There are many ways of weight initialization:
1. Initialization with zeros
Initialization with zeros will result in no learning at all. The left most figure in the following diagram shows a graph between the Training Loss VS Epochs for training a simple CNN over MNIST dataset. The batch size was 128 images and no. of Epoch were 12.
2. Initialization with ones
3. Initialization with constants
4. Initialization with Normal Random Values (
mean, stddev, seed)Initialization with values with normal distribution
5. Initialization with Uniform Random Values
(minval, maxval, seed)6. Initialization with Truncated Normal Random Values(
mean, stddev, seed)7. Initialization with Variance Scaled Values (
scale, mode, distribution, seed)